
The AMBER workflow begins with an agreement that allows AMBER to work with your media files to identify wildlife targets.
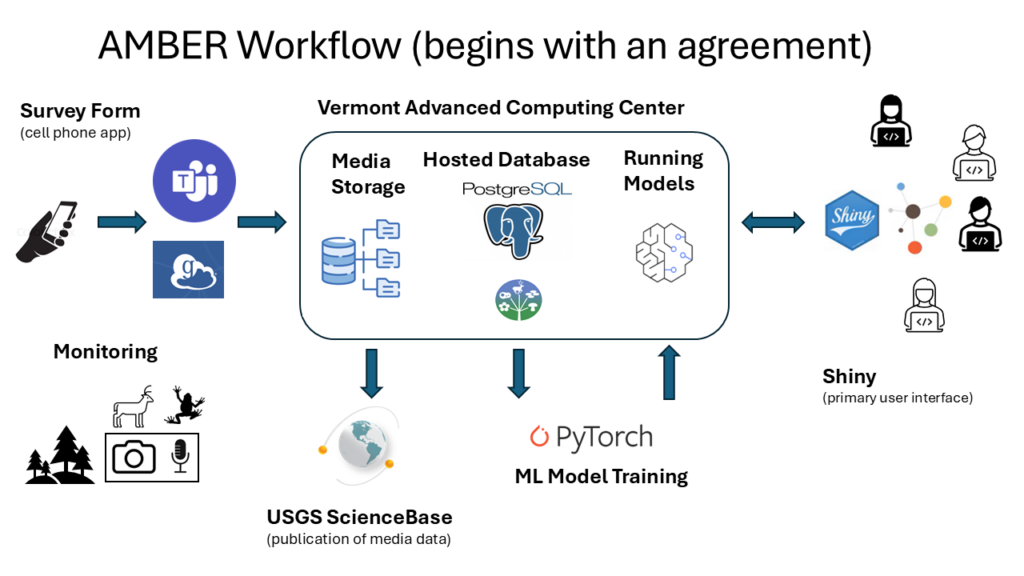
The AMBER workflow depicts the data processing steps, namely (1) Data collection via remote monitoring devices (lower left of diagram); (2) Collection of site visit metadata via Survey123; (3) Transfer of collected media data via Globus; (4) Storage of media data in UVM research storage (Netfiles) and storage of metadata in a Postgres database, hosted on a UVM virtual machine; (5) Data portal allowing access to media files and metadata via a dedicated, hosted Shiny app; (6) Analysis of data via machine learning models via the Vermont Advanced Computing Center (VACC); (7) The ability to easily export data for subsequent analysis using R/RStudio; and (8) publication of datasets via USGS ScienceBase. The AMBER workflow and data pipeline has been used to process millions of photos and audio files for over a dozen monitoring projects, with resulting datasets having been released in the public domain via the AMMonitor ScienceBase community: https://www.sciencebase.gov/catalog/item/6188c0c4d34ec04fc9c4f7a4.